
![[de]](/mwf/flags/de.png "Germany")
Hello dear forum,
I am currently developing an OpenClonk editor with C# and Visual Studio 2012. Currently looks like this:
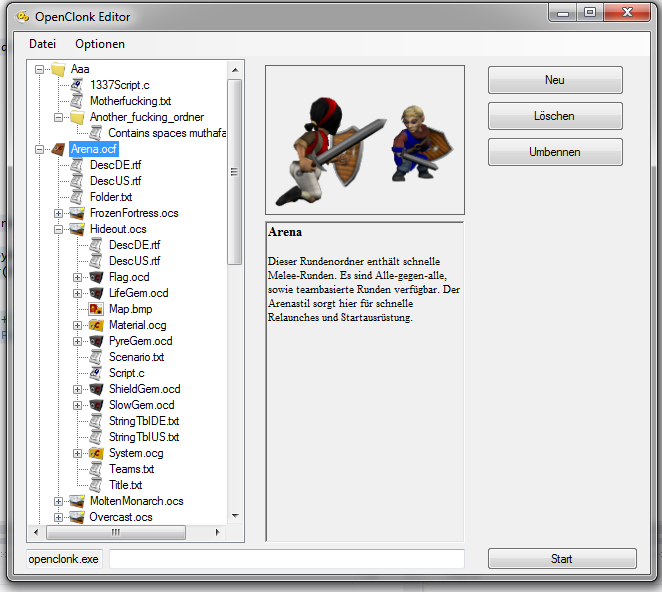

My problem is the performance. When clicked at a Szenario, GameFolder or Object, it tries to view a preview, namely to display a DescDE.rtf / DescUS.rtf and a Title.png (for objects: parse the StringTblDE.txt / StringTblUS.txt for Name and Description). When the node has not been unpacked yet (It's a .ocs / .ocd / .ocf FILE, it only gets unpacked when the user clicks the plus) it Unpacks the whole .ocs file (only as an example), tries to find a Description rtfs and a title.png, loads these into the window, and then packs the whole previously unpacked file again. This is not very fast, as it has to Unpack the whole file, search for the relevant files and then pack the thing again. The c4group.exe does not have the possibility to command it to only extract a specific file.
So I took a look at the C++ source in the c4group folder. I could locate where the arguments are being parsed, but I just couldn't figure out how I can modify the source sothat I can specify a "--unpack-only" parameter, folowed by the file I want to extract from the .ocs / .ocd / .ocf.
That's why I can only sincerely ask for your help.
Well, or, I could just disable the previews. But then, my editor would be missing something that even the CR Editor could :(
I am currently developing an OpenClonk editor with C# and Visual Studio 2012. Currently looks like this:
My problem is the performance. When clicked at a Szenario, GameFolder or Object, it tries to view a preview, namely to display a DescDE.rtf / DescUS.rtf and a Title.png (for objects: parse the StringTblDE.txt / StringTblUS.txt for Name and Description). When the node has not been unpacked yet (It's a .ocs / .ocd / .ocf FILE, it only gets unpacked when the user clicks the plus) it Unpacks the whole .ocs file (only as an example), tries to find a Description rtfs and a title.png, loads these into the window, and then packs the whole previously unpacked file again. This is not very fast, as it has to Unpack the whole file, search for the relevant files and then pack the thing again. The c4group.exe does not have the possibility to command it to only extract a specific file.
So I took a look at the C++ source in the c4group folder. I could locate where the arguments are being parsed, but I just couldn't figure out how I can modify the source sothat I can specify a "--unpack-only" parameter, folowed by the file I want to extract from the .ocs / .ocd / .ocf.
That's why I can only sincerely ask for your help.
Well, or, I could just disable the previews. But then, my editor would be missing something that even the CR Editor could :(
 Loading has always been pretty slow(?)
Loading has always been pretty slow(?)But I suppose you would never actually unpack and re-pack an existing file (that would change the author etc.). So I guess CR unpacked that into a temporary folder and then just deleted it? (no need to pack it again!)
 Why don't you just include the c4group source code directly and use its internal functions to edit files? Those support extraction of single components.
Why don't you just include the c4group source code directly and use its internal functions to edit files? Those support extraction of single components.
Because I'm writing in C# and source is c++? I wouldn't quite know how to do that. All I've done yet with "external code" was once importing a .dll and calling functions in that. Is it possible to produce a .dll file from c4group that lets me extract single files out of .ocs / .ocd / .ocf etc.?
![[gb]](/mwf/flags/gb.png "United Kingdom")
Certainly possible, but from what the Internet tells me you'd essentially have to break everything down to a C-level interface before that. That might involve a bit of leg work...
The second option would be to port C4Group to C# - that's what C4DT ends up doing when it needs to look into packed files from Java (see for example here). That would involve even more programming work, even though I might add that it's actually "just" gzip-compressed binary data, so there's nothing earth-shattering going on.
Generally it would still seem the most sensible solution to rely on c4group, even with its admittedly minimal interface. It could probably be extended a bit - but without major reworking the best you could probably do would be to provide a new option to get to
That's the options you have, from my point of view.
The second option would be to port C4Group to C# - that's what C4DT ends up doing when it needs to look into packed files from Java (see for example here). That would involve even more programming work, even though I might add that it's actually "just" gzip-compressed binary data, so there's nothing earth-shattering going on.
Generally it would still seem the most sensible solution to rely on c4group, even with its admittedly minimal interface. It could probably be extended a bit - but without major reworking the best you could probably do would be to provide a new option to get to
C4Group_CopyItem, as even if you added "--unpack-only" you'd run into the fact that C4Group_UnpackDirectory / C4Group_ExplodeDirectory are not really meant to be restricted. Note though that you will never be able to match the speed of the CR frontend this way, as you will close and re-open the file in question each time, whereas CR simply left the file open and repositioned the file pointer as needed.That's the options you have, from my point of view.
Implementing a reader for c4group is relatively trivial if you have something to decode gzip/deflate.
 Not really, there is still lots of details going on. Of course it should be a bit easier to read if you work on bytestreams and zip on a day-to-day basis, but I guess most people don't do that.
Not really, there is still lots of details going on. Of course it should be a bit easier to read if you work on bytestreams and zip on a day-to-day basis, but I guess most people don't do that.
I suspect that Java isn't the ideal language to read bytestreams. I think even my PHP-Version was shorter.
Mh, right, if you asked me what Java is the ideal language for... I can't come up with anything. It's not especially easy with C++ either, though. Efficient and good-lucking implementations of BigInt!

> Mh, right, if you asked me what Java is the ideal language for... I can't come up with anything.
Eclipse plugins and the html validator.
"the" html validator? The w3c-page is what comes to my mind when you say that. Same thing?
There was an SGML validator that was called the HTML validator when used with the HTML4 DTD, but that has been obsolete for years. I meant the contemporary HTML validator, which has earned the "the" by virtue of being the only one implementing the current HTML standard. I think the W3C runs a copy of that somewhere, too, if W3C branding matters for you.
 You find 150 LOC too long?
You find 150 LOC too long?
>Is this from you?
Yes.
>Are you implementing that for C4DT?
No, I was techdemoing stuff for my desktop client to download and synchronize save games and addons (e.g. CCAN). But it could be used for anything.
I think C4Group is already in its own library. So making it a DLL should be as easy as just changing a few compiler options.There's also a set of C4Group_* functions that can be exported, so you do not need to export any class structures.
There's no particular reason for C4Group to be slow except a somewhat stupid implementation. It'd be nice to get that optimized.
I don't know if x changed, but writing out 000-files as cache certainly counts as a stupid implementation.
You mean while packing? Right now the only alternative would be to keep the contents of the 000-files in memory - which the engine should already do for small files. For larger files falling back to the hard drive is actually the right thing to do, I feel (even though memory sizes are so large these days that it starts becoming less true).
What we'd actually need to do a better job would be some sort of "C4Group builder" interface (like string builder for strings), I feel. Would also need some format adjustments, as you wouldn't know the size of sub-groups beforehand, so you'd have to "rewind" in order to put in sizes. That might be... tricky in a compressed stream. But might be possible - maybe you could deactivate compression for the headers, then seek back or something.
What we'd actually need to do a better job would be some sort of "C4Group builder" interface (like string builder for strings), I feel. Would also need some format adjustments, as you wouldn't know the size of sub-groups beforehand, so you'd have to "rewind" in order to put in sizes. That might be... tricky in a compressed stream. But might be possible - maybe you could deactivate compression for the headers, then seek back or something.
No, while unpacking.
Packing sequentially without keeping the files in ram doesn't work, that's right. On the other hand side, I haven't seen a group in a while that wouldn't fit in the RAM of my oldest machine, and that one is 12 years old...
Packing sequentially without keeping the files in ram doesn't work, that's right. On the other hand side, I haven't seen a group in a while that wouldn't fit in the RAM of my oldest machine, and that one is 12 years old...
Unpacking will not generate temporary files. Except when you unpack to disk, at which point that's expected behaviour, isn't it?
I don't get how temporary files are expected behavior when unpacking to disk, but... Whatever, I'm not going to change anything about it.

>Motherf*king.txt
>Another_f*king_ordner
>Contains spaces muthafa...

I was too busy coding to think of mature folder and filenames to test my program^^
Not having to do my own thinking is the purpose of standards. In this case, the Foo, Bar, Baz and Lorem Ipsum and Bla, Blub standards. Having words that only mean "no meaning" isn't as meaningless as it sounds and really quite useful. I wish we had more of them. I almost always use "foo" etc., and sometimes I need more than three, and get annoyed about wasting a decision on such trivialities.

Powered by mwForum 2.29.7 © 1999-2015 Markus Wichitill
